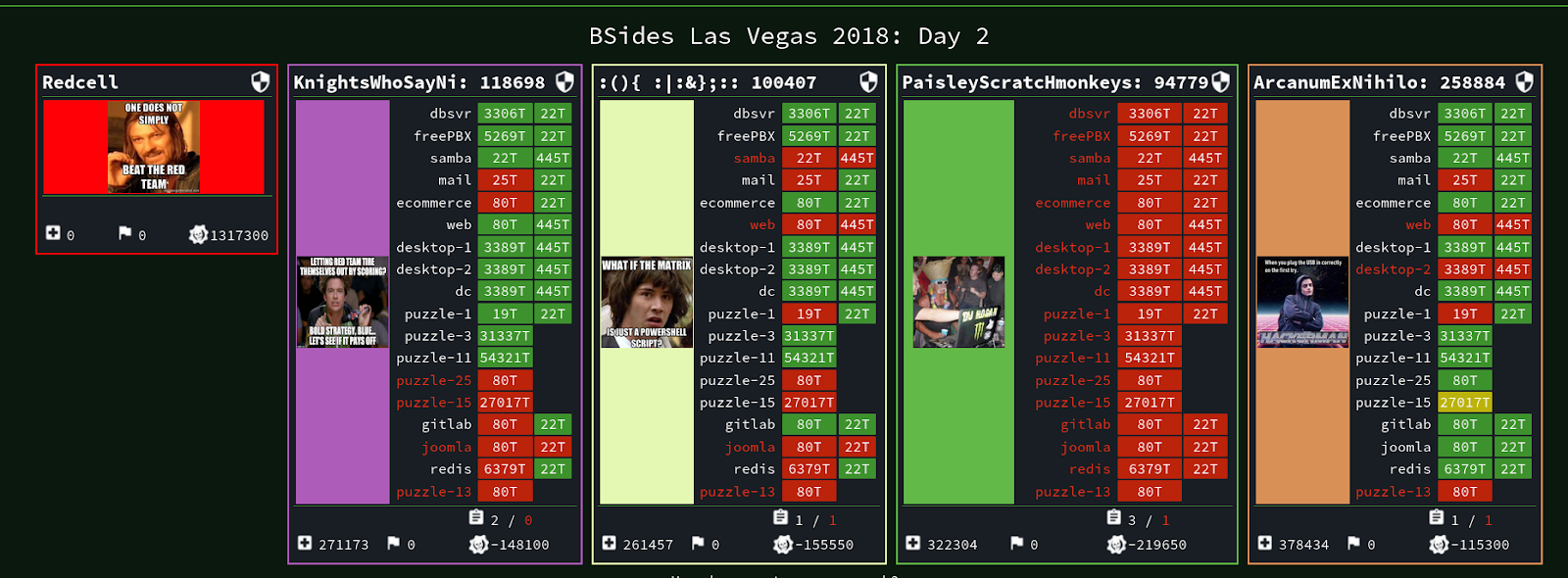
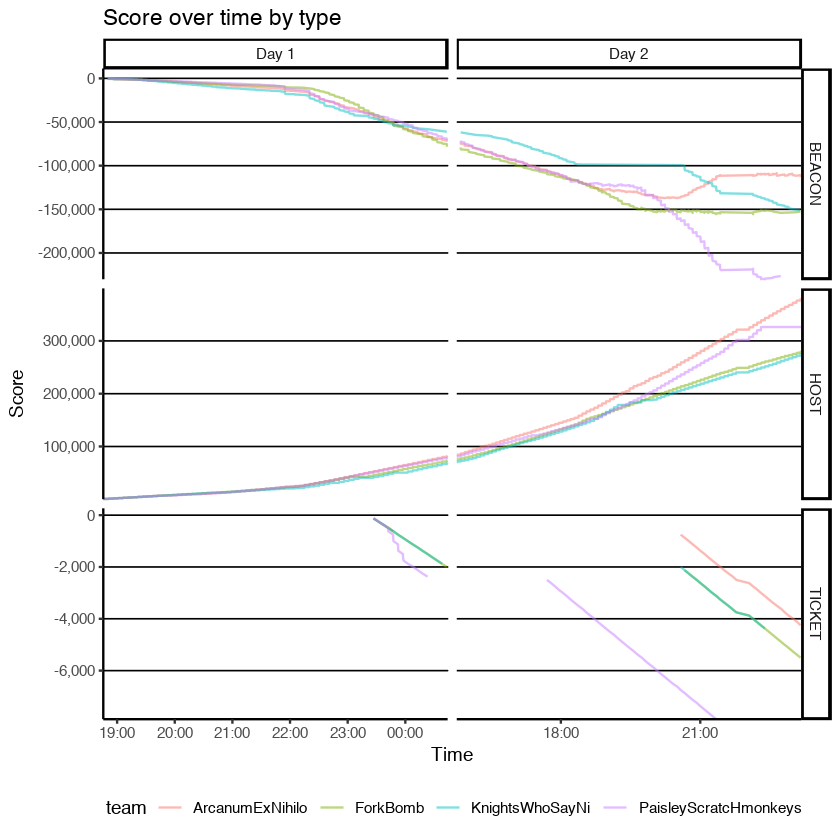
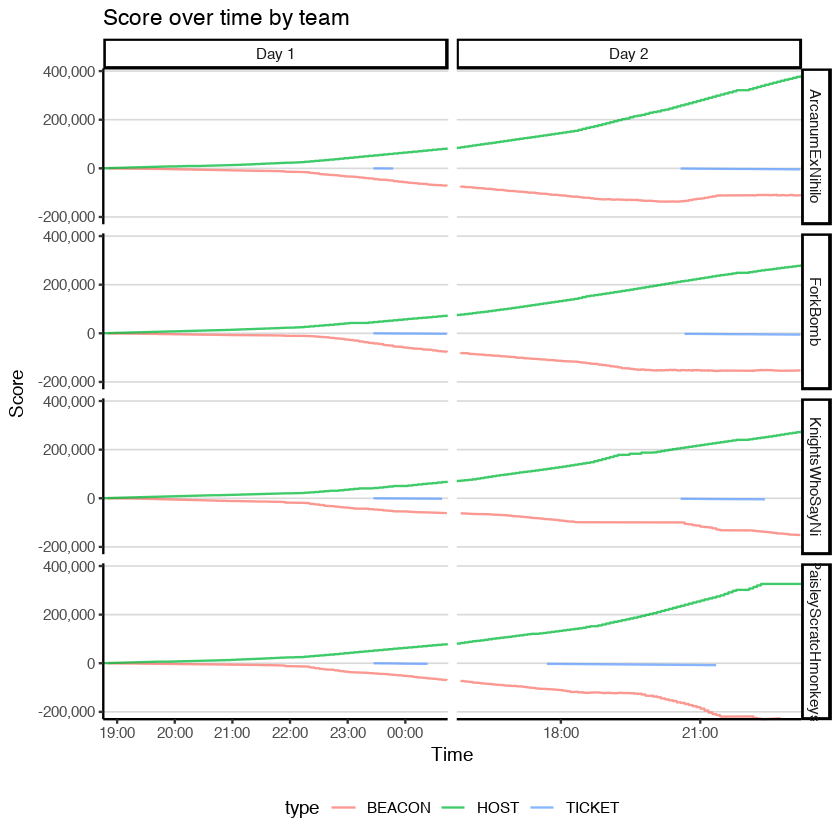
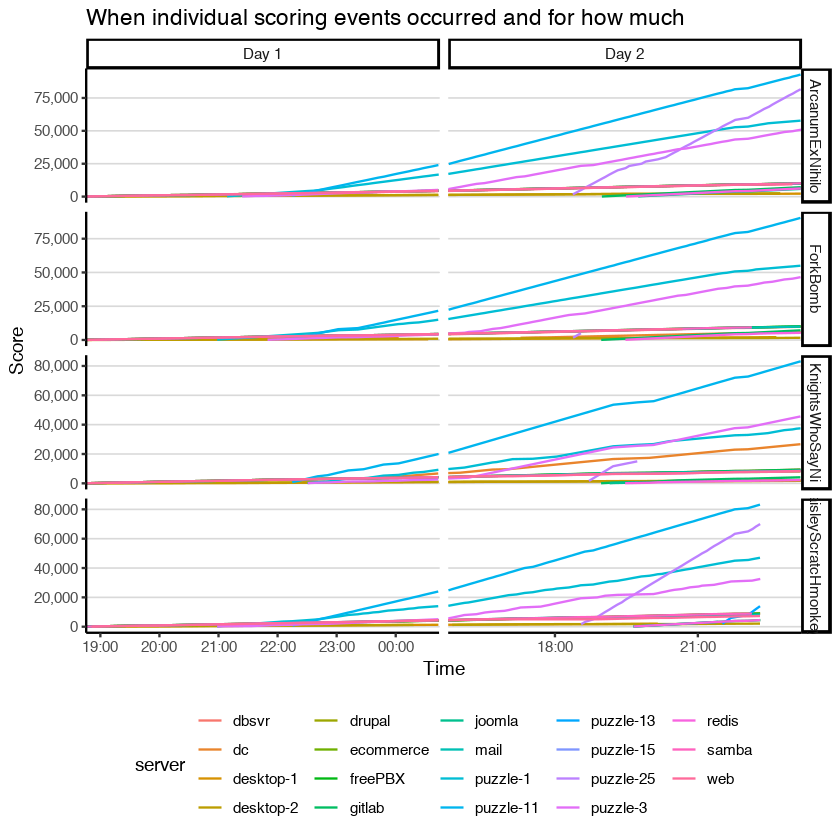
It's been a while since I've updated CAGS. This is an initial post and may be modified to better fit with CAGS 2 later.
Revision: Schema updated to 3.2. See the previous 3.X schema(s) at the end of this post.
3.2 Schema
- All property names must be stored as lower case
- The graph must be a directed multigraph. It must be a combination of a causal bipartite multigraph with 'context, 'objects' (previously conditions, a subtype of context), and 'actions' (previously events) representing the two types of nodes and a knowledge simple graph defined in OWL used to describe the objects and actions.
- Action node properties. All other properties should be defined through the knowledge graph.
- type: "action" (required)
- id: A URI including the graph prefix identifying the node (required)
- name: The action that occured. This may be from a schema such as a VERIS action or ATT&CK technique, or may be an arbitrary string describing the action or event that took place. (required)
- start_time: The time the atomic the node represents began to exist. Time should be in ISO 8601 combined date and time format (e.g. 2014-11-01T10:34Z). If no time is available, minutes since unix epoch (1/1/1970 Midnight UTC) should be used as a sequence number. (required)
- finish_time: The time the atomic the node represents ceased to exist. Time should be in ISO 8601 combined date and time format (e.g. 2014-11-01T10:34Z) (optional but encouraged)
- logic_operator: a function (including the language the function is defined in) that takes the state of parent objects to the node as arguments (pre-conditions) and returns the effect(s) on child objects to the node (effects). (A characteristic borrowed from formal planning.) This may be ladder logic, first order logic, higher level languages such as python, machine learning model, etc. The values accepted per pre-condition and produced per effect must be in the same set as values used for the object node state property. In practice this will often be the identity function. (For example if a parent object's state is 'compromised', after the action the child object's state will be compromised. If missing, is assumed to be the identity operator transfering the set of all state from precursor objects to affected objects.
- succeeded: float from 0 (failed) to 1 (succeeded) or distribution representing the probability that action succeeded in its effects. Any effects which may be separable should be defined through a separate action. (optional)
- confidence: float from 0 to 1 or distribution representing the confidence that the action succeeded. (optional)
- Context node properties. All other properties should be defined through the knowledge graph. These definitions may take the from of an existing schema such as VERIS assets, the CARS data model objects, or other ontologies of objects defined through a knowledge graph.
- type: "context" or "object" (required)
- id: A URI including the graph prefix identifying the node (required)
- Object node properties. Object nodes are a sub-type of context in that they may be instanced and have a 'state' which changes as actions are applied. Only object nodes may be part of the causal graph.
- state: A property that may be used as a transient string representing the state of the object during a point in time representing the current state of the system. The sum of all object states is the state of the system. This may be as simple as "compromised", from an ontology such as VERIS attributes, the Confidentiality, Integrity, Availability triad, Bayesian or DIMFUI (Degradation, Interruption, Modification, Fabrication, Unauthorized Use, and Interception), or it may even be an arbitrary string.
- Edge Properties:
- source: the id of the source node. Object nodes may only have sources of action nodes and action nodes may only have sources of object nodes. All nodes part of the knowledge graph may only have sources within the knowledge graph or an object node. (required)
- destination: the id of the destination node. Object nodes may only have destinations of action nodes and action nodes may only have destinations of object nodes. All nodes part of the knowledge graph may only have sources within the knowledge graph or an object node. (required)
- type: Edges between actions and objects (in either direction) have a type from the set of states acceptable for the object node state property and must agree with the pre-conditions and effects of the action node involved's logic operator. All other edges are defined by the OWL knowledge schema. (required)
- The acceptable edge types are: "precursor_of" (edge from an object to an action), "effect_of" (edge from an action to an object), "describe" (edge from an object or context to an object, context, or action).
- id: A URI representing the edge. (optional)
- It is intended that sets of nodes and edges in the graph can be joined to create a subgraph represented by a single node. The node must still obey all previous schema requirements.
Strengths
This schema builds on the 2.0 and 3.0 schemas in a few fundamental ways:
- The use of knowledge graphs to provide properties simplifies defining arbitrary sets of properties. This is incredibly important as different users will want to represent different properties at different levels of detail. In Figure 1, Object 3 is a process linked to it's higher level representations. However the dotted lines show how Objects 5-8 could be used if the goal was a higher level representation of the incident.
 |
| Figure 1 - Knowledge graph used to represent different levels of description. |
- The use of a logic operator allows for arbitrary logic in progressing through the graph without creating complex graph structures to try and define the logic. This effectively replaces the Bayesian Conditional Probability Tables in version 2.
- The action-object bipartite graph provides the ability to represent complex relationships (as a bipartite graph can represent hypergraphs and simplicial complexes, or dendrites) while still maintaining the strengths of traditional graphs. It allow allows moving almost all properties to nodes or to the knowledge graph.
- The use of properties defined without schemas (action node action, action node logic operator, object node knowledge graph, and object node state) allows the schema to be "specifically vague" (credit to Gage for the term). Enough to be clear but vague enough to support varying use cases.
- The set of object states is the state of the system the graph describes. To determine the state of the graph at given time, all actions must be applied in order. This provides for state management without state explosion.
Limitations
- The schema does not define how parent-child relationships are established (though it is logical that children must come after parents and that parents/children are limited by the objects an action requires tas pre-conditions and the objects it may affect.
- The schema does not define how to identify duplicate objects within the graph (where a a single actual object is represented by two object nodes). When a schema is not used to help avoid duplication, I envision tools that tools will be available to help identify duplicates through their knowledge graph properties. OWL allows for the same object to exist as different notes in the same knowledge graph.
- The schema does not readily distinguish between ground truth and records used to observe ground truth. Care must be taken to distinguish these two types of actions and the associated objects. For example, a record may be an object child of the action that generated it. Figure 2 provides an example. The characteristics of the record can be as simple or as detailed as desired though it's prudent to consider the ability of the graph to scale to represent instances of records.
 |
| Figure 2 - Representing logs of what happened |
- The schema does not explicitly define actor, however it may be a relationship established in the knowledge graph and is considered a best practice.
Example
The following image provides an example based on an incident from the VERIS Community Database (VCDB), specifically case a2ed36db-0c78-4162-b2cc-dbaa2ca73866. (Note that the example leaves out the majority of the properties for brevity.)
 |
| Figure 3 - Example incident |
Representations
At its core, the schema is incredibly simple as can be seen below:
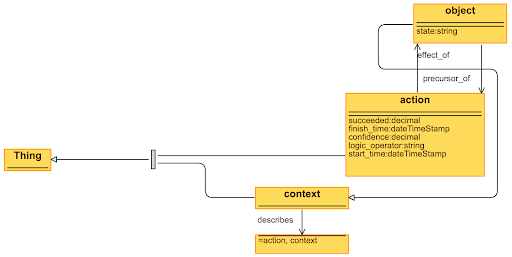
This OWL file can be found here. CAGS graphs conforming to this format should be stored as triples in JSON-LD format. If converting to a property graph, the graph should be stored in JSON Graph Format (JGF).
Use Cases
Aggregation of Events
Log data comes in as atomic events. Given any single event, timestamps only reveal that later events cannot be the parent and earlier events cannot be the child, but the timestamp does not explain _what_ the parent(s) or child/children of an event are.
The graph schema should assist in determining the parent(s) and child/children of an event, (for example by defining that an event occurred due to a file, a credential, or another system and, as such, that object(s) or actions ending in that object(s) must contain the parent.
Motif Communication
It is often helpful when communicating a plurality of actions to communicate the relationships between those actions. This really will touch on multiple use-cases, but is centered around motifs as bounded portion of a path or subgraph.
Attack Surface
A system can be documented using the graph schema to identify the interconnectivity between components and highlight potential paths of attack. (Note, while many of the prior use cases are based around events (or signal generated from the system, this is based on the _actual_ state of the system and actual actions rather than the events they generate.)
Attack Graph Generation
An attack surface generated using the graph schema can be used to plan potential attacks on the system. This can be used for automated attack simulation such as cauldera, planning manual penetration testing (such as bloodhound), etc. This likely results in an attack graph, (a plurality of actions to take).
Analysis
Event data should be able to be aggregated into paths and graphs. This data can then be aggregated across data sources (different tools, sites, organizations, etc) and then queried using graph queries to identify commonalities such as common motifs.
Incident Documentation
After an incident has occurred, the incident responders can document the relationship between the observed actions (or events generated by those actions) using the graph schema.
Detection
A defender wants to define a detection that contains multiple atomic events and how they are related (such as in grapl). To do this they need both a motif of the detection and the ability to aggregate events to see if they match the motif.
Simulation
A defender may wish to simulate attacks containing more than a single event. To do so they need a motif of events and their relationships and the ability to turn that into atomic actions to take/attempt to take.
Incident Response
After aggregating events, the data can be analyzed using graph tools, neural networks, or other tools to identify things like missing edges (actions the attackers might have taken but where no event exists to document it), nodes (objects that may be involved in the incident, but are currently not included in the investigation), or clustering (to identify assets currently part of the investigation but are unlikely to have been involved).
Defense Planning
Given analysis of an attack surface producing an attack graph, the attack graph can then be analyzed to determine thing such as what events will be generated if exercised, nodes and edges central to the attack that might serve as optimal mitigation points, etc.
Risk Analysis
Given an attack surface, analyze the graph to identify the overall 'risk' associated with it. The goal is to provide quantitative feedback on the likelihood and potentially impact of cyber threats given threat intelligence.
3.1 SCHEMA
The 3.1 schema is the same as the 3.2 schema except for the following changes:
- The CAGS 3.1 'uuid' property has been replaced with an 'id' which uses URIs including graph namespaces instead of UUIDs
- CAGS 3.2 adds allowed edge types
- CAGS 3.2 adds 'context' nodes
- Added representations
- Described logic_operator as optional but with a default representation if missing
- Renamed the 'action' property of actions to 'name'
3.0 SCHEMA
The attack flows are defined with nodes as objects and their individual actions as hyperedges. Nodes maintain their individuals state with respect to security while edges document how state is changed by the edge. Edges also contain the logic to adjudicate complex interactions between inputs. The attack flow (or graph) in its entirety represents the state of the system (or portion of the system) being described.
NODES TYPES:
- Datum
- Person
- Storage
- Compute
- Memory
- Network
- Other
- Unknown
Nodes have a ‘state’ property representing their current state with respect to the actor. They indicate the states (confidentiality/integrity/availability, Create/Read/Update/Delete, or object-specific).
EDGES:
- leads_to
Edges are hyperedges (or, alternately, a bipartite representation of hyper-edges) with with a ‘logic’ property defining the process for translating the inputs into a success at the output. Another option is to model the edge as a dendrite to represent the input to output logic of the edge.
Edges have a ‘action’ property defining the details of the action. (These may be in ATT&CK, veris, or any an arbitrary language.)
Edges may have a timestamp property to indicate the order in which they occur. In practice this can be ‘played’ on the graph to update the node states over time.